In the high-stakes race for AI supremacy, Google has unveiled a contender that’s challenging the fundamental “bigger is better” philosophy dominating the field. Meet Gemma 3, the lightweight AI model that’s punching well above its weight class.
Unlike industry giants needing vast server farms, Google’s Gemma 3 runs on modest hardware. The model sizes (1B, 4B, 12B, and 27B parameters) show efficiency. Notably, the 27B parameter model rivals larger models like DeepSeek-V3’s 671B parameters using just one NVIDIA H100 GPU, unlike competitors that require up to 32 GPUs for similar performance.
Swiss Army Knife Intelligence
What makes Gemma 3 particularly intriguing isn’t just its efficiency but its versatility. Unlike many specialized models, Gemma 3 seamlessly processes text, images, and even short videos. This multimodal capability opens doors for applications ranging from visual question answering to generating stories based on images.
The model’s multilingual prowess is equally impressive—offering out-of-the-box support for 35 languages and pre-trained compatibility with over 140. This global reach makes it particularly valuable for companies operating across international markets.
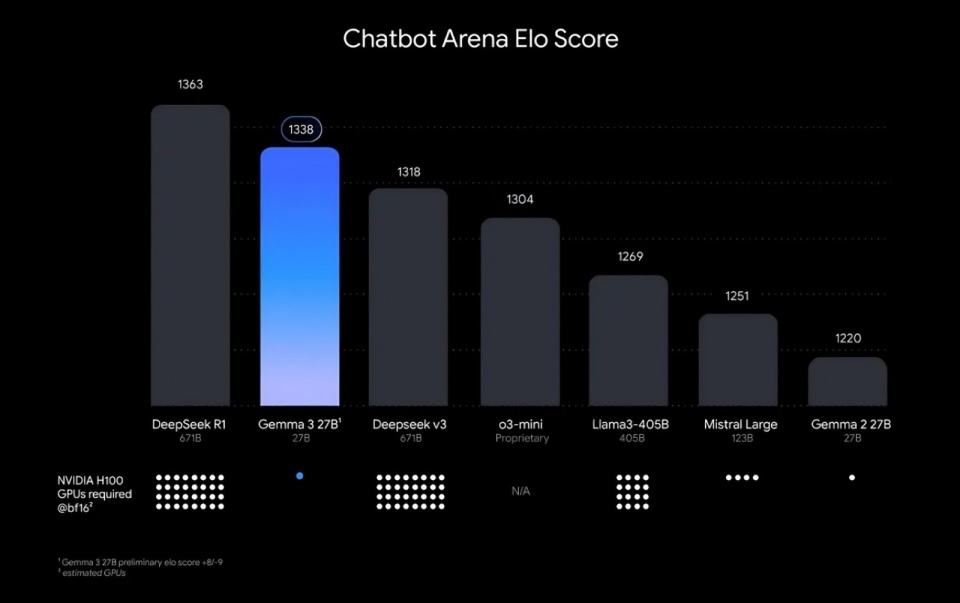
By The Numbers
Benchmark performance reveals Gemma 3’s competitive edge. It scored 67.5% on MMLU-Pro, 42.4 on GPQA-Diamond, and an impressive 89 on MATH-500. While specialized models occasionally edge it out in specific domains, Gemma 3 maintains a strong balance across diverse tasks.
More telling are human preference evaluations. On the LMArena leaderboard, Gemma 3 27B has registered an Elo score of 1338, outperforming DeepSeek-V3’s 1318 and o3-mini’s 1304. These scores are particularly remarkable considering the vast difference in model size—Gemma 3 achieves this with just 27B parameters compared to DeepSeek-V3’s 671B.
The Triple Threat: Speed, Cost, and Compute Efficiency
Gemma 3’s most impressive achievement may be its trifecta of efficiency advantages:
Compute Efficiency
The model achieves near-state-of-the-art performance while using dramatically fewer computational resources. In direct comparisons, Gemma 3 reaches 98% of DeepSeek-R1’s Elo score using only a single NVIDIA H100 GPU—a feat that would typically require multiple high-end accelerators.
Cost Implications
This efficiency translates directly to the bottom line. The reduced hardware requirements mean significantly lower deployment costs, making advanced AI capabilities accessible to startups, academic institutions, and businesses with limited IT budgets. The energy savings are equally substantial, addressing growing concerns about AI’s environmental impact.
Speed of Output
Gemma 3’s blistering speed sets it apart in an industry where responsiveness often takes a backseat to raw capabilities. The smaller models in particular showcase impressive performance metrics—the 1B variant processes an astonishing 2,585 tokens per second during prefill operations.
To put this in perspective, that’s roughly the equivalent of reading and comprehending an entire page of text in a fraction of a second.
This rapid processing enables near-instantaneous responses in real-time applications, creating a fluid user experience that feels remarkably human. The speed advantage is particularly noticeable in contexts where immediacy matters:
- Mobile applications, where users expect instant responses despite limited device resources
- IoT devices and embedded systems that require efficient on-device processing
- Interactive customer service bots that need to maintain conversational flow
- Edge computing scenarios where cloud connectivity may be limited or unreliable
While Gemma 3 excels in most scenarios, it’s worth noting that it occasionally lags behind in highly specialized execution-heavy tasks. Complex animations, scientific simulations, or intricate 3D rendering may still benefit from models specifically optimized for those narrow use cases. However, for the vast majority of real-world applications, Gemma 3’s speed-to-capability ratio makes it the more practical choice.
The Secret Sauce
How does Gemma 3 achieve such efficiency? Google’s technical documentation points to neural network distillation and architectural modifications aimed at reducing memory requirements. The model’s advanced quantization techniques minimize computational demands while maintaining high speeds—a crucial factor in its ability to outperform much larger models.
The engineering approach stands in stark contrast to competitors like DeepSeek-V3 and o3-mini, which rely on hundreds of billions of parameters or highly specialized architectures. Instead, Gemma 3 demonstrates that strategic architecture design can be more important than raw parameter count or narrow optimization.
Getting Your Hands on Gemma 3
Google’s commitment to democratizing AI access is evident in how easily developers can start using Gemma 3. The model is available through multiple channels designed to accommodate different user needs:
No-Setup Exploration
For those looking to experiment immediately, Google AI Studio offers browser-based access to the full-precision model without any installation requirements. Users can simply sign up and begin interacting with Gemma 3 instantly.
Developers ready to integrate the model into their applications can obtain an API key directly from Google AI Studio and utilize Gemma 3 through the Google GenAI SDK, streamlining the development process.
Development and Customization
More advanced users can download the model from popular AI platforms including Hugging Face, Ollama, or Kaggle. This flexibility allows developers to choose their preferred environment.
Particularly impressive is Gemma 3’s adaptability. The model can be easily fine-tuned to specific needs using Hugging Face’s Transformers library or any other preferred development environment. This makes it straightforward to customize the model for specialized applications without extensive resources.
The accessibility of Gemma 3 stands in stark contrast to many leading AI models, which often require substantial technical expertise and computational resources just to get started.
The Future of Efficient AI
As the AI industry grapples with the environmental and economic costs of ever-larger models, Gemma 3 offers a compelling alternative narrative. Its remarkable performance with just 27B parameters suggests that efficiency optimization may be as important as raw parameter count in advancing AI capabilities.
For developers and enterprises looking to deploy advanced AI without breaking the bank, Gemma 3 represents a watershed moment. It demonstrates that sometimes, less really is more—especially when “less” has been engineered to be exceptionally efficient.
In a field obsessed with size, Gemma 3 is proving that intelligence isn’t just about scale—it’s about design.
References
- Introducing Gemma 3: The most capable model you can run on a single GPU or TPU (https://blog.google/technology/developers/gemma-3/)
- Gemma 3 Technical Report (https://storage.googleapis.com/deepmind-media/gemma/Gemma3Report.pdf)
- Gemma 3 on mobile and web: https://developers.googleblog.com/en/gemma-3-on-mobile-and-web-with-google-ai-edge/