You’ve been there. You ask Claude Code to refactor the auth middleware. It proposes server-side rendering (SSR). You explain, once again, that the PM vetoed SSR six months ago for analytics reasons. The agent apologizes, adjusts, and delivers solid work.
Next week, a new session. Same agent, same suggestion. The context is gone.
This isn’t a bad model. It’s a missing layer. AI coding agents read codebases, reason about architecture, and write production-grade code. But they have a fundamental limitation that no amount of model improvement will fix: they don’t remember what they learned yesterday.
Every session starts from scratch. Hard-won insights evaporate. And without memory, the agent makes decisions without context it should have had. It upgrades the dependency that was pinned for a reason, proposes the architecture that was explicitly rejected, re-investigates the bug that was already root-caused two sessions ago. Each amnesiac session isn’t just inefficient. It’s a fresh opportunity for a mistake that memory would have prevented. And it gets worse as projects age, because the gap between what the agent could know and what it does know widens with every session.
NotebookLM as agent memory
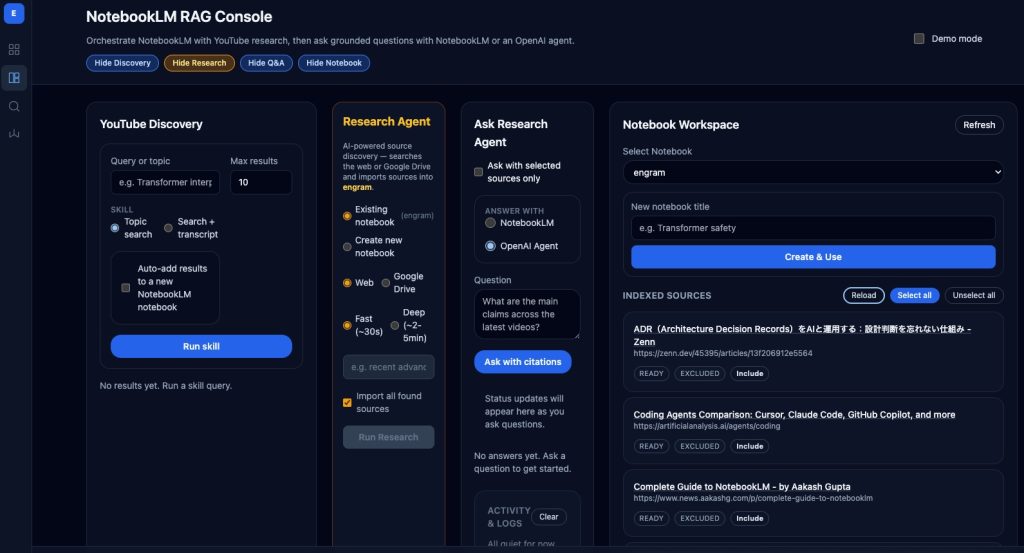
NotebookLM is Google’s tool for grounded Q&A over curated sources. You add documents (design specs, post-mortems, meeting notes, debugging logs) and query them with retrieval-augmented generation. Every answer comes with citations back to the source material.
The insight behind Engram is that this is exactly the memory layer coding agents need. Instead of building custom RAG infrastructure (vector databases, embedding pipelines, chunking strategies), you use NotebookLM as an external brain that the agent queries at the start of each session and writes back to at the end.
What makes this different from a generic vector DB is grounding. When the agent learns that “the payment service returns 202 for async operations,” it also gets a citation pointing to the exact source: the architecture doc, the post-mortem, the checkpoint from a previous session. With a generic RAG setup, you get text chunks with no chain of custody. You can’t tell if a snippet is from an authoritative design doc or an abandoned draft. Grounding is what makes the memory trustworthy, and trust is what lets the agent act on it without asking you to confirm.
The learning loop
The agent’s workflow becomes a four-phase cycle that turns each session into a node in a growing knowledge graph.
1. Bootstrap. Before writing code, the agent queries the notebook: “I’m about to add idempotency to payment retries. What should I know?” NotebookLM returns relevant context from previous sessions. When the question touches shared concerns (infrastructure, dependencies, debugging patterns), the bootstrap automatically queries other tracked project notebooks and synthesizes the combined context.
2. Iterative research. If the first answer is too general, the agent asks follow-ups. After each answer, it checks for gaps: undefined references, missing implementation details, uncovered edge cases, cross-domain blind spots, and stale information. The agent keeps going until it has implementation-level detail or identifies a knowledge gap the notebook can’t fill.
3. External research. When the notebook doesn’t have the answer, the agent triggers NotebookLM’s research capability to import external sources: documentation, blog posts, Stack Overflow threads, academic papers. It can also search YouTube for conference talks, capture transcripts, and add them as sources. A 45-minute StripeCon talk on webhook idempotency patterns becomes a citable, queryable source that every future session can draw from. Engineering knowledge increasingly lives in video. With transcript ingestion, it becomes queryable alongside everything else.
4. Checkpoint. When the agent discovers something non-obvious (a root cause, an implicit coupling, an environment quirk), it writes it back to the notebook. A webhook queue lets the human review each checkpoint before it enters the knowledge base. You approve the genuine insight. You reject the obvious. The notebook stays curated.
Session after session, the notebook gets smarter. The third session knows what the first discovered and the second confirmed.
Beyond project memory
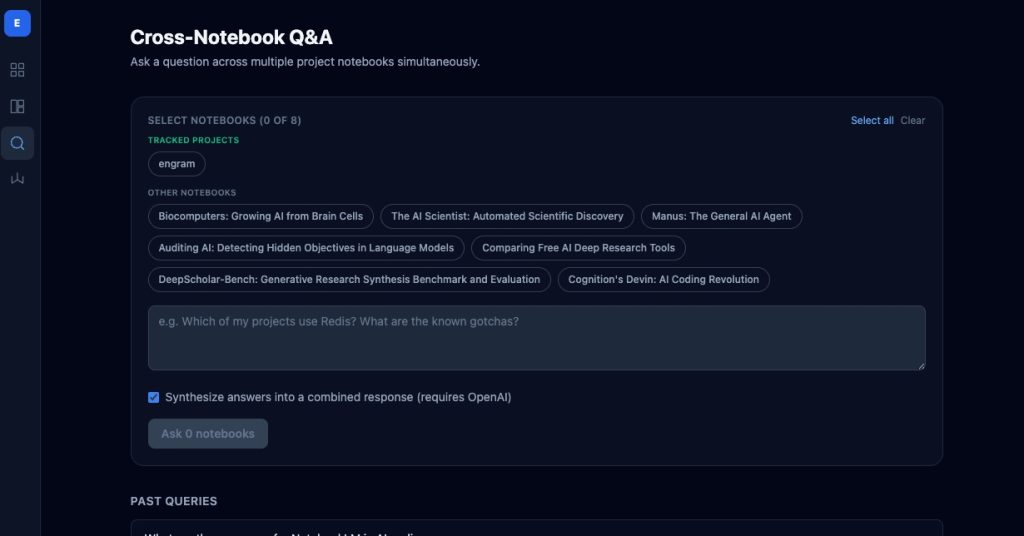
Per-project memory is necessary but not sufficient. The payments team’s discovery about Stripe rate limits is relevant when the orders team builds retry logic. The auth team’s session-token gotchas matter when the mobile team implements token refresh.
Engram’s cross-notebook Q&A queries multiple project notebooks in parallel and synthesizes the answers into a single response, with citations attributed by project. But cross-notebook Q&A alone is a point-in-time action. The insight was produced but never propagated. Knowledge flowed out of the notebooks into a single conversation but didn’t flow back.
Memory evolution
This is where the architecture shifts from retrieval to something closer to how organizational knowledge actually works. The principle: knowledge discovered in any project should propagate to every project it’s relevant to, automatically.
This aligns with recent research on agentic memory. A-MEM (Xu et al., 2025) showed that new memories should trigger updates to existing memories’ context and links. Agent KB (2025) demonstrated that cross-domain knowledge reuse improved SWE-bench resolution rates by 12 percentage points.
Three mechanisms close the loop:
Auto-triggered cross-QA at bootstrap. The bootstrap detects whether a question touches cross-project concerns using keyword matching. If triggers match, it automatically queries other project notebooks in parallel. Agents don’t know what they don’t know. An agent on the orders service has no way to know that payments already solved the exact retry problem it’s about to encounter. The system detects when cross-project knowledge is relevant and provides it.
Cross-QA sync. After a cross-notebook query produces a synthesized answer, syncing pushes it back to each participating notebook as a source. The next time any of those projects bootstraps with a related question, the insight is already there. New knowledge enriches existing knowledge stores.
Cross-project checkpoints. When an agent discovers something with cross-project implications, it submits the checkpoint with a cross-project flag. On human approval, the checkpoint is pushed to all tracked project notebooks. A staging quirk discovered by the payments team is immediately available to every other agent.
Each cycle (bootstrap, discover, checkpoint, propagate) leaves every notebook richer than before. This is the difference between a team where each member has a good memory and a team that has shared institutional knowledge.
The economics: offloading to Google
NotebookLM offloads both storage and analysis to Google’s infrastructure. The coding agent doesn’t index documents, build embeddings, or manage retrieval.
Token savings. A bootstrap query returning a 200-word grounded answer replaces 5,000+ tokens of raw context files loaded every session.
Research doesn’t burn agent tokens. Web research, Drive search, and YouTube transcript analysis all happen server-side. One API call replaces reading pages into the context window.
Storage is free and unlimited. No per-vector charges, no hosted database costs. The knowledge base grows at zero marginal cost.
The agent stays focused on what it’s good at: reading code, reasoning about changes, writing implementations.
The compounding advantage
Most discussions about AI coding agent capabilities focus on single-session improvements: better reasoning, longer context windows, more tools. These matter. But they’re session-scoped improvements to a fundamentally session-scoped tool.
Memory changes the unit of improvement from sessions to projects. Memory evolution changes it from projects to organizations.
By session 10, the agent has a curated, cited knowledge base assembled incrementally from real work. But session 10 on the orders service also knows what session 5 on payments discovered about Stripe, because that checkpoint was flagged as cross-project. And the auth service knows the infrastructure lesson the billing agent learned, because a cross-QA synthesis was synced back.
The notebook doesn’t just remember facts. It remembers reasoning, provenance, and relationships between discoveries. “The timeout is 30 seconds” is a fact the code contains. “The timeout is 30 seconds because the payment provider hangs for 20s under load, discovered during the March incident, confirmed by an imported Stripe support thread, and the orders team hit the same issue two weeks later.” That’s organizational memory. The difference between an agent that writes correct code and one that writes code surviving contact with production.
The missing piece
We’ve spent two years making AI coding agents smarter but mostly ignored that they forget everything between sessions and never share what they learn. A senior engineer who lost their memory every night would be useless within a week. A team of brilliant engineers who never talked to each other would be almost as bad.
The next session should start smarter than the last one ended. And so should every session on every project that shares the same concerns.
Your agent is already smart enough. It just needs to remember, and to share what it remembers.
Source. Engram is open source and available at github.com/ngstcf/engram.