📌 Research Project: Experimental AI-Assisted Screening
This is an exploratory research prototype, intended for experimentation and learning, and does not reflect a production HR system or official UNU hiring policy.
Exploring AI-Assisted CV Screening
This research prototype explores how AI might assist with initial CV screening by reviewing job descriptions and evaluating CVs against specific requirements. It organizes and ranks applicants to help identify potential matches — with human judgment always leading the final decision.
The 3-Step Workflow
Step 1: Load Job Description
First, provide the job requirements. You have three options:
- Paste URL: The AI will crawl the live job posting.
- Upload File: Upload a PDF or HTML file of the job description.
- Upload JSON: Load a previously saved
.jsonfile to skip parsing.
Job Parsing Level
When uploading a URL or File, you must choose a level:
- Level 1 (Strict): Extracts skills from "Qualifications" ONLY.
- Level 2 (Deep): Extracts skills from "Qualifications" + "Responsibilities".
Important Note: When using Level 2 (Deep Parse), the final candidate evaluation will list "Missing Required Skills" from *both* the Qualifications and Responsibilities sections. This is more comprehensive but may result in more "gaps" being identified.
How Skill Requirements (AND/OR) are Interpreted
The AI reads skill lists to set a required_count for each group:
"React, Node, and SQL"setsrequired_count: 3(Needs all)."React or Vue"setsrequired_count: 1(Needs one)."e.g., Laravel, Symfony"setsrequired_count: 1(Needs one).
Candidates are then evaluated against this "required count" for each skill group.
Step 2: Upload Candidates
Upload your candidate files. You can drag and drop multiple files at once.
CVs (Required)
Upload the candidates' CVs or resumes (.pdf, .docx). This is the primary document for the evaluation.
Q&A (Optional, but Recommended)
Upload a corresponding text file (.txt, .md, .pdf, .docx) with pre-screening question answers for each candidate.
Why? This allows the AI to cross-reference the CV (what they *say* they did) against their answers (how they *think* and *communicate*), leading to a much deeper and more accurate analysis.
File Pairing Requirement
The system pairs files one-to-one. You have two options:
- Upload **zero** Q&A files (CVs only).
- Upload a Q&A file count that **exactly matches** the number of CVs.
(e.g., 3 CVs and 2 Q&A files will result in an error).
🛡️ PII Scrubbing (Enabled by Default)
Recommended: The system automatically scrubs Personally Identifiable Information (PII) before sending documents to the AI, helping reduce bias and protect privacy.
- Date of Birth – Removed to prevent age-related bias
- Gender – Removed to prevent gender-related bias
- Nationalities – Removed to prevent nationality-related bias
This option can be toggled off if needed for your specific use case.
Step 3: Evaluate & Review
This is where the magic happens. This flexible workflow allows you to get multiple perspectives on your candidates.
1. Configure Your Analysis
Before processing, you have two main controls:
- Select AI Model (Accordion 1): Choose your "brain" (Gemini, OpenAI, etc.). You can change this later to get a "second opinion".
- Select Evaluation Prompt (Accordion 3): Choose your "instructions" (Basic, Moderate, Advanced). This tells the AI *how* to analyze and what to look for.
2. Execute & Review
- Process: Click the "Process Candidates" button to run the full analysis.
- Review: Analyze the ranked, color-coded candidate cards in the "Formatted Results" tab.
- Save: On the "Parsed Job Description" tab, click "Save JSON" to save your parsed JD for future use.
Iterate with the "Re-run" Feature
This is the most powerful feature. If you want a different perspective, you don't need to re-upload. Just change your settings (like the AI Model or Evaluation Prompt) and use one of the two Re-run options:
- Re-run Evaluation (Fast): Re-uses the already-parsed data for a new analysis in seconds.
- Re-parse & Evaluate (Slow): Use this *only* if you've edited the *CV parsing logic* itself. It re-reads the original files from scratch.
Job Parsing Prompt Comparison
Imagine a job description says:
- Qualifications: “Must have Python.”
- Responsibilities: “Deploy microservices using Kubernetes.”
Scenario A: Job Parsing Level 1 (Strict) + Extended Evaluation
Job Parsing (L1): The "target list" for skills is just [Python].
Evaluation (Extended):
- required_skills (40% weight): The AI checks "Does the candidate have Python?" It completely ignores "Kubernetes" in this section because it wasn't on the L1 target list.
- responsibility_alignment (35% weight): The AI separately reads the job's responsibilities and checks the candidate's CV for “Did this person ever deploy microservices?” This is where it would analyze their experience with Kubernetes.
Scenario B: Job Parsing Level 2 (Deep) + Extended Evaluation
Job Parsing (L2): The "target list" for skills is
[Python, Kubernetes].
Evaluation (Extended):
- required_skills (40% weight): The AI now checks “Does the candidate have Python?” AND “Does the candidate have Kubernetes?” If they don't, it will be listed as a missing required skill.
- responsibility_alignment (35% weight): The AI performs the same check: “Did this person ever deploy microservices?”
Conclusion
Level 2 prompt moves "Kubernetes" from a "nice-to-have" context for responsibility alignment into a "must-have" item for the required skills score, which significantly impacts the final grade.
Education & Experience: Alternative Pathways (OR Logic)
Many job descriptions offer alternative pathways for meeting education and experience requirements. The AI system is designed to interpret these as OR conditions — not AND conditions.
How Alternative Pathways Work
When a job description contains multiple experience requirements with different education levels and year requirements, these are interpreted as alternatives. A candidate needs to meet ONLY ONE of the pathways — not all of them.
Example Scenario
"experience_requirements": [
"6 years in software development with a High school diploma (required)",
"4 years in software development with a Bachelor's degree (required)"
]
Correct Interpretation (OR Logic):
| Candidate | Education | Years | Status |
|---|---|---|---|
| A | High school diploma | 6+ | ✅ Qualified |
| B | Bachelor's degree | 4+ | ✅ Qualified |
| C | Master's degree | 4+ | ✅ Qualified |
| D | High school diploma | 4 | ❌ Not qualified |
| E | No degree | 10+ | ❌ Not qualified |
Key Principle
Higher education level can substitute for lower education level with the same or fewer years. A Master's degree holder meets the Bachelor's pathway requirement, and exceeding the years requirement with a lower education level also qualifies.
AI Providers: Parsing & CV Screening
The system supports multiple AI providers for both job description parsing and CV screening. Below is the tested compatibility status for each operation.
| Provider | JD Parsing (URL) | JD Parsing (PDF) | CV Screening | Notes |
|---|---|---|---|---|
| Azure OpenAI | ✅ | ✅ | ✅ | Fully tested & recommended |
| DeepSeek | ✅ | ✅ | ✅ | Fast & affordable |
| OpenAI | ✅ | ✅ | ✅ | Fully tested |
| Anthropic | ✅ | ✅ | ✅ | Fully tested |
| Google Gemini | ✅ | ✅ | ✅ | Fully tested |
| Groq | ⚠️ | ⚠️ | ⚠️ | Not tested for CV screening |
| Ollama | ✅ | ✅ | ✅ | Works! Quality varies by model - use 70B+ for best results |
Recommendation
For best quality, use Azure OpenAI, DeepSeek, OpenAI, Anthropic, or Gemini. Ollama works for local/remote deployments but quality varies by model size - use larger models (70B+) for better structured output. All providers offer full compatibility with URL and PDF parsing as well as CV screening.
Core Features
Flexible AI Engine
You're in control. Choose from OpenAI, Azure OpenAI, DeepSeek, Anthropic, Gemini, Groq, or a local Ollama model. Get a 'second opinion' from a different AI to ensure a fair evaluation and mitigate model bias.
Instant Re-Evaluation
This is transparency in action. Don't like the AI's focus? Edit the evaluation instructions and click "Re-run". Get a new analysis based on your new rules in seconds, without re-uploading.
The Unbreakable Prompt Editor
Our editor is split into three parts. You only edit **Part 1 (Instructions)**. The system automatically appends **Part 2 (Data)** and **Part 3 (Format)**, making it impossible to accidentally break the prompt.
Advanced Recency Analysis
Go beyond simple skill matching. The 'Advanced' mode checks *when* skills were used, flags outdated_skills, and adds a recency_note to certifications.
Dynamic Ad-Hoc Analysis
Ask any ad-hoc question. The AI will place the answer in a special additional_findings section. Ask to "analyze publication relevance" and get a direct answer without breaking the UI.
AI-Powered Evaluation
The system performs a deep analysis by following the instructions from your selected prompt. It identifies strengths, gaps, and compensation precisely because the prompt (which you control) tells it to.
Application UI
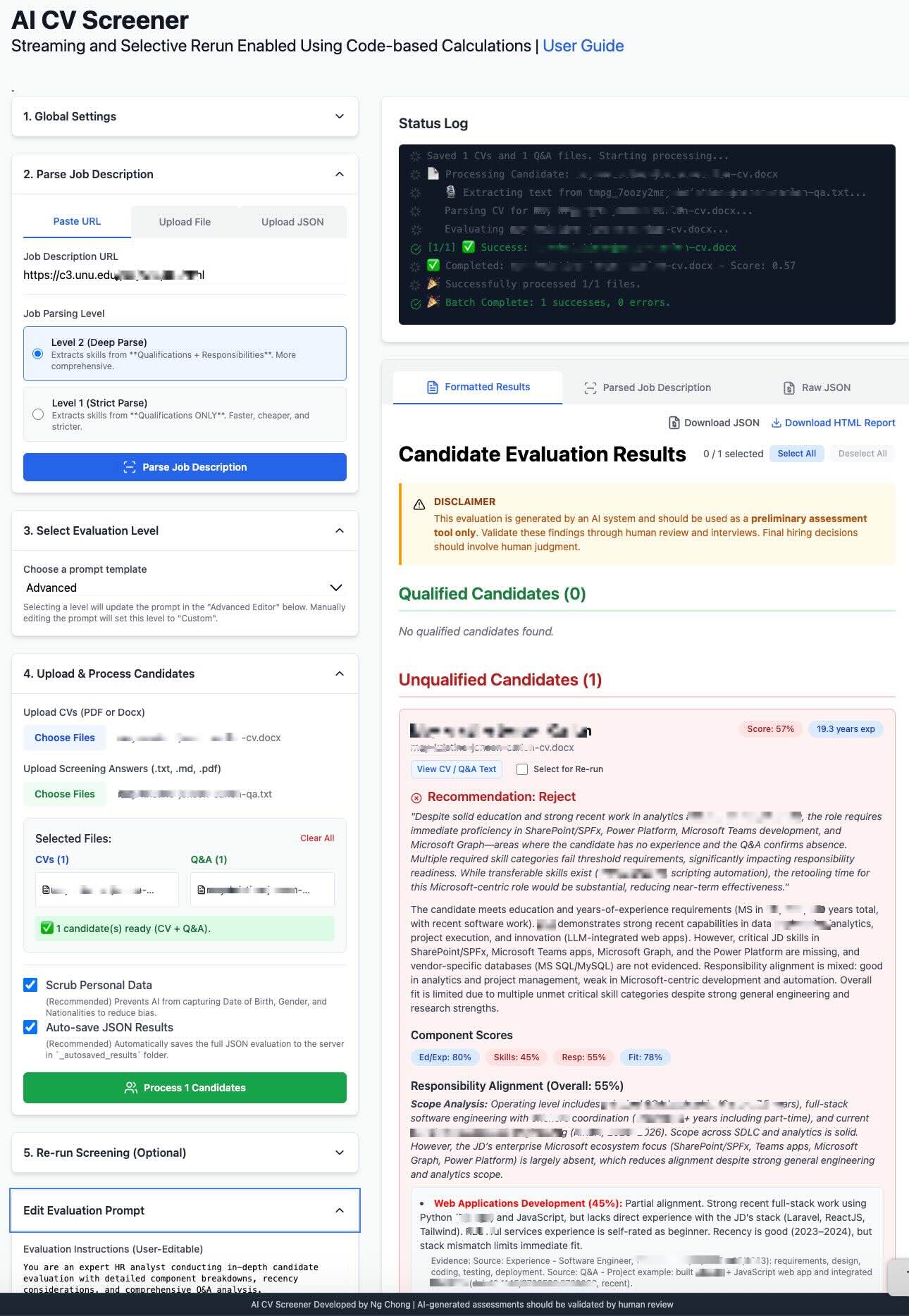
The Role of the Q&A File: From Tie-Breaker to Primary Evidence
📋 What "Q&A" Means Here
Q&A refers to written screening questionnaires sent to candidates at application time (before interviews). Candidates provide written responses that are later cross-referenced with their CV by the AI. These are not live interview questions.
Uploading Q&A files is optional, but it dramatically improves the quality of your evaluation. The CV shows **"what"** a candidate has done; the Q&A shows **"how"** they think, communicate, and solve problems.
The "weight" given to the Q&A file is not a magic number, but a set of **explicit, written instructions** in each prompt. As you select a higher level, the AI is forced to rely more heavily on the Q&A as proof.
Scenario 1: Weak Q&A *Pulls Score Down*
- CV (Source 1) claims: "Expert in AWS (EC2, S3, ECS, EKS)"
- Q&A (Source 2) reveals: "I have not used ECS/EKS professionally, but read the docs..."
- AI's Conclusion: The Q&A directly contradicts the CV. The AI flags this as a **Red Flag** (Overstatement). The scores for "Skills" and "Responsibility Alignment" are actively lowered, despite the CV claim.
Scenario 2: Strong Q&A *Pulls Score Up*
- CV (Source 1) claims: "Developed various web apps." (Vague)
- Q&A (Source 2) reveals: "I use JWTs for auth, HttpOnly cookies, and rate-limiting..."
- AI's Conclusion: The AI follows the rule "If the Candidate Profile is weak but Screening Answers are strong, give weight to the answers". The Q&A provides *expert proof* of skills that were only implied on the CV, actively pulling the "Skills" and "Responsibility Alignment" scores higher.
Scenario 3: The "Hidden Strength"
- CV (Source 1) claims: (No mention of Python)
- Q&A (Source 2) reveals: Demonstrated ability to write complex Python automation scripts.
- AI's Conclusion: The AI treats this as a **Hidden Strength**. It gives a "Partial Bonus" to compensate for gaps but adds an **Interview Flag** to verify why the skill was omitted.
| Conflict Scenario | AI Interpretation | Impact on Score |
|---|---|---|
| CV says Yes, Q&A says No | Red Flag (Overstatement) | Significant Penalty (Reduces Score) |
| CV says No, Q&A says Yes | Hidden Strength (Scenario 3) | Partial Bonus (Compensates for gaps) |
| CV is Vague, Q&A is Strong | Validation (Scenario 2) | Increases Confidence & Score |
Advanced Level Scoring Process
The scoring for the Advanced level is a two-step process that uses both sets of weights. This ensures that both the candidate’s documented experience (CV) and their demonstrated understanding (Q&A) contribute to the final evaluation outcome.
Step 1: Calculate the Four Component Scores (55% CV / 45% Q&A)
The system first determines the individual 0–1 scores for each of the four components: Education, Skills, Responsibility, and Fit.
- CV Evidence: 55% weight
- Q&A Evidence: 45% weight
This means a strong CV alone is not enough — if Q&A performance contradicts the CV, the score for that component is penalized proportionally to the inconsistency.
Example
For the Required Skills component, a candidate’s CV might show 5 years of recent experience with a technology. However, if their Q&A responses are vague or outdated, the 45% Q&A weight will reduce the component score substantially.
- Strong CV + Weak Q&A → Major concern (significant penalty)
Step 2: Calculate the Final Score (20% / 40% / 35% / 5%)
After Step 1 produces the four component scores, they are combined using the following weighted formula:
| Component | Weight |
|---|---|
| Education & Experience | 20% |
| Required Skills | 40% |
| Responsibility Alignment | 35% |
| Cultural Fit | 5% |
Final Score =
(Education & Experience × 0.20)
+ (Required Skills × 0.40)
+ (Responsibility Alignment × 0.35)
+ (Cultural Fit × 0.05)
In short, the 55%/45% split defines how each component score is derived, and the 20%/40%/35%/5% split defines how those component scores are mathematically combined into a single final score.
Step 3: Example Calculation — Required Skills Breakdown
The required_skills score (weighted at 40%) is the average of four skill-area scores.
Each skill category is analyzed as follows:
Final Category Score = (Base Ratio) × (Recency Multiplier) × (Q&A Multiplier)- Base Ratio (from CV): Candidate’s skill match ratio.
Formula: candidate_skills / required_count - Recency Multiplier (from CV): Adjusts for how current the experience is (1.0 recent (< 3 years), 0.8 dated (3-5 years), 0.5 outdated (>5 years))
- Q&A Multiplier: Reflects Q&A validation strength (1.0 strong, 0.9 adequate, 0.7 weak, 0.4 contradiction).
Example Calculation — Category 1 (Cloud Platforms)
- Base Ratio = 1.0 (3 of 3 skills listed)
- Recency Multiplier = 0.8 (last used 4 years ago)
- Q&A Multiplier = 0.4 (contradictory responses)
Category 1 Score: 1.0 × 0.8 × 0.4 = 0.32
This illustrates how the 55%/45% process operates: the CV creates a solid foundation (55%), while the Q&A response (45%) validates or penalizes it.
Step 4: Average Across Skill Categories
The four category scores are averaged to produce the final required_skills score.
| Category | Score | Notes |
|---|---|---|
| Category 1 | 0.32 | Strong CV, weak Q&A |
| Category 2 | 0.90 | Strong CV, strong Q&A |
| Category 3 | 0.70 | Adequate Q&A, slightly dated |
| Category 4 | 0.56 | Partial CV match, adequate Q&A |
Final Required Skills Score: (0.32 + 0.90 + 0.70 + 0.56) / 4 = 0.62
Interpretation
A score of 0.62 means that despite strong CV claims, the weak Q&A validation significantly reduced the final skill rating. This demonstrates how CV–Q&A discrepancies heavily impact the final score.
What Determines 'Qualified' vs. 'Unqualified'?
This is not a magic guess. The qualified flag is an objective, pass/fail test based on a set of rules that **you control** through two main levers:
1. Your Job Parsing Level (The "Input")
This defines the *list* of 'required skills' the AI will check against.
- Level 1 (Strict): The AI's list *only* includes skills from the "Qualifications" section. This is an easier bar for candidates to pass.
- Level 2 (Deep): The AI's list includes skills from *both* "Qualifications" and "Responsibilities." This is a harder, more comprehensive bar.
2. Your Evaluation Prompt (The "Rules")
This defines the *logic* for the pass/fail test. Each prompt level has stricter rules:
- Basic: Checks only minimum education and experience.
- Moderate: Checks for education, experience, *and* critical skills.
- Advanced: Checks for education, experience, critical skills, *AND* recency of evidence.
Important: 'Qualified' vs. 'Recommendation'
These are two separate concepts. Use them together to make the best decision:
qualified: **The Objective Flag.** It asks, "Did the candidate meet my absolute minimum, non-negotiable rules?"recommendation: **The Subjective Judgment.** It asks, "Based on the *whole picture* (including Q&A, preferred skills, and 'fit'), should we talk to this person?"
This separation is powerful. You might get a candidate who is qualified: false (missing one rule) but has a recommendation: "Interview with Reservations" (because they are exceptional everywhere else). This allows *you* to make the final, nuanced decision.
The 5 Evaluation Prompt Levels
Choose the level of detail you need. The "data-aware" UI will automatically adapt to show all available information, from a simple score to a complex, multi-part assessment.
📋 BASIC - Quick Pass/Fail Screening
Best for: High-volume initial screening, junior roles, clear-cut requirements.
What it does:
- Checks if candidate meets absolute minimum requirements (education, years of experience, critical skills).
- Simple pass/fail assessment - no nuance.
- Lists only critical gaps (deal-breakers).
Role of the Q&A File (Weight: ~5-10%)
At this level, the Q&A file is used only as a "Tie-Breaker." It is ignored unless the CV is too ambiguous to make a simple pass/fail decision.
Example JSON Output:
A minimal JSON object is returned, focusing only on the pass/fail criteria.
{
"qualified": false,
"score": 0.2,
...
"gaps": [
{
"gap": "Fails to meet minimum 5 years of experience.",
"critical_to_role": true,
"compensated_by_other_strengths": "Not compensated"
}
],
"summary": "Candidate is unqualified...",
"recommendation": "Reject"
}
🎯 MODERATE - Balanced Assessment (Default)
Best for: Most hiring scenarios, mid-level roles, balanced decision-making.
What it does:
- Assesses minimum requirements + overall fit quality.
- Evaluates skill alignment and depth.
- Lists ALL gaps (critical + non-critical) with impact assessment.
- Explains how other strengths compensate for gaps.
Role of the Q&A File (Weight: ~20%)
The Q&A is used as "Supporting Evidence." It helps the AI judge "overall fit" and communication tone, which influences the final summary and recommendation.
Example JSON Output:
The JSON now includes strengths and a more detailed gaps array.
{
"qualified": true,
"score": 0.78,
"strengths": [
"Meets 5+ years experience requirement.",
"Strong evidence of leading teams of 3-5 engineers."
],
"gaps": [
{
"gap": "Lacks experience with Kubernetes (required skill).",
"critical_to_role": true,
"compensated_by_other_strengths": "Not compensated - significant concern."
},
{
"gap": "No PMP certification (preferred skill).",
"critical_to_role": false,
"compensated_by_other_strengths": "10+ years leading projects demonstrates practical expertise."
}
],
"summary": "Candidate is qualified and has strong leadership skills...",
"recommendation": "Interview"
}
🔍 COMPREHENSIVE - Weighted Multi-Dimensional Analysis
Best for: Senior roles, leadership positions, strategic hires.
What it does:
- Everything in Moderate, PLUS:
- Weighted scoring framework: Skills (40%) + Responsibilities (35%) + Education (20%) + Fit (5%).
- Deep
responsibility_alignmentanalysis (3-5 key responsibility areas evaluated individually). - Assesses scope, scale, and complexity of past experience vs. job requirements.
Role of the Q&A File (Weight: ~35%)
The Q&A is now a "Key Influencer." It is used to validate claims for the high-weight (40%) "Skills" and (35%) "Responsibility Alignment" scores. A weak Q&A will actively pull down the final score.
Example JSON Output:
The JSON now features the critical responsibility_alignment object with individual scores.
{
"qualified": true,
"score": 0.82,
...
"responsibility_alignment": {
"key_areas": [
{
"area": "Network Security Infrastructure Management",
"assessment": "Candidate has 5 years managing network security... but no direct experience with the required Cisco ASA platform.",
"match_score": 0.72
},
{
"area": "Vendor and Stakeholder Communication",
"assessment": "Extensive evidence of effective communication with non-technical stakeholders...",
"match_score": 0.93
}
],
"overall_score": 0.825
},
...
"recommendation": "Recommend with Reservations"
}
🔬 EXTENDED - Deep-Dive with Mandatory Tables
Best for: Executive roles, highly specialized positions, forensic evaluation.
What it does:
- Everything in Comprehensive, PLUS:
component_scores: A full breakdown of all 4 weighted areas.skills_assessment: Tables of skills met, missing, preferred, and transferable.red_flags: Analysis of employment gaps, job hopping, etc.growth_trajectory: Analysis of the candidate's career pattern.interview_focus_areas: Specific questions to probe gaps and concerns.
Role of the Q&A File (Weight: ~40%)
The Q&A is now a "Mandatory Component." The AI is required to cross-reference the CV and Q&A and produce a structured qa_analysis_report, identifying strengths and concerns found *only* in the Q&A. It is now on equal footing with the CV.
Example JSON Output:
This is the most detailed JSON, including all analytical components for the "data-aware" UI.
{
"qualified": true,
"score": 0.84,
"component_scores": { ... },
"skills_assessment": {
"required_skills_met": [ ... ],
"required_skills_missing": ["Azure", "GCP"],
...
},
"qa_analysis_report": {
"overall_assessment": "The Q&A responses are strong... (etc.)",
"key_strengths_revealed": ["Confirmed Laravel expertise not obvious on CV."],
"concerns_raised": ["Lacks depth on specific CI/CD tools mentioned."]
},
"red_flags": ["Frequent job changes (2015-2018)"],
"growth_trajectory": "Candidate shows a clear ascending pattern...",
"recommendation_rationale": "A strong architect with proven leadership...",
"interview_focus_areas": [
"Probe on multi-cloud knowledge.",
"Discuss reasons for job changes prior to 2018."
]
}
🚀 ADVANCED - Forensic Analysis with Recency & Currency
Best for: Fast-evolving fields (tech, AI, cybersecurity), roles requiring cutting-edge knowledge.
What it does:
- Everything in Extended, PLUS:
- **Recency & Currency Assessment**: The AI actively searches for *when* skills were used.
- The
skills_assessmentnow includesoutdated_skills(e.g., "Hadoop, last used 2020"). - Key skills get a
recency_note(e.g., "Certification expired 2022"). - Gaps analysis will now include
recencyas a category.
Role of the Q&A File (Weight: ~45%+)
The Q&A is now the "Primary Validator" for currency. The AI is instructed to pay special attention to the *recency* of knowledge in the Q&A. A dated CV can be "saved" by a modern Q&A, and a strong CV can be "flagged" by an outdated Q&A.
Example JSON Output:
The JSON output is identical in structure to Extended, but the *content* is now focused on recency.
{
/* ... (Same fields as Extended) ... */
"skills_assessment": {
"required_skills_met": [
{
"skill": "PyTorch",
"proficiency_evidence": "Used extensively at DataCorp (2021-2024).",
"years_experience": 4,
"recency_note": "Current and active. Most recent usage within last 3 months."
}
],
"outdated_skills": [
"Hadoop administration (last used 2020, technology declining)",
"Cloudera CDH (certification expired 2022)"
]
},
"gaps": [
{
"gap": "Experience with Hadoop/Spark is dated (last used 4+ years ago).",
"category": "recency",
...
}
]
}
Dynamic Ad-Hoc Analysis
Use Case: You have a specific, one-off question not covered by the standard prompt.
How it works:
Simply add your question to any prompt (Basic, Moderate, etc.) in the "Advanced Editor".
Your Custom Instruction:
"Evaluate the candidate... (all other instructions) ... Produce an assessment statement about the candidate's leadership skills."
Resulting JSON (The AI adds the additional_findings block):
{
"qualified": true,
"score": 0.78,
...
"additional_findings": [
{
"title": "Leadership Skills Assessment",
"finding": "The candidate demonstrates strong leadership potential. They managed a team of 3 developers at their previous role and led a successful microservices migration project. This aligns well with the 'team lead' responsibilities of the role."
}
]
}
Quick Comparison Table
| Feature | Basic | Moderate | Comprehensive | Extended | Advanced |
|---|---|---|---|---|---|
| Review Time | 30 sec | 2-3 min | 5-7 min | 10-15 min | 15-20 min |
| Pass/Fail | ✅ | ✅ | ✅ | ✅ | ✅ |
| Gap Analysis | Critical only | All gaps | All gaps + impact | All gaps + detailed | All gaps + recency |
| Responsibility Alignment | ❌ | ❌ | ✅ Detailed | ✅ + Evidence | ✅ + Recency |
| Q&A Analysis | Verify claims (factual only, no compensation) | Depth validation (affects scoring) | Multi-aspect (skills, approach, communication) | Mandatory + multipliers (1.0x/0.9x/0.7x/0.4x) | Primary validator for currency |
| Red Flags | ❌ | ❌ | ❌ | ✅ | ✅ Enhanced |
| Growth Trajectory | ❌ | ❌ | ❌ | ✅ | ✅ + Momentum |
| Recency Assessment | ❌ | ❌ | ❌ | ❌ | ✅ Multipliers |
| Interview Prep | ❌ | ❌ | ❌ | ✅ | ✅ Comprehensive |
Q&A Verification Behavior by Level
Each evaluation level treats Q&A responses differently. Understanding these differences helps you choose the right level and interpret results correctly.
📋 Basic: Verify-Only (One-Way Fact-Checking)
Direction: CV → Q&A (confirm claims only)
What Happens with Verification Outcomes
| Q&A Result | Impact |
|---|---|
| ✅ Confirms CV claim | Strengthens pass determination |
| ❌ Contradicts CV claim | Red flag + potential fail |
| ⚠️ Inconsistent with CV | Red flag (overstatement detected) |
| 🚫 CV has no claim | Ignored — cannot compensate |
Example: CV claims "Expert in Vue.js" but Q&A says "never used Vue professionally" → Red flag added, candidate may fail
Key: Binary pass/fail per category. No partial credit. Q&A cannot create new qualifying evidence.
🎯 Moderate: Depth Validation (Affects Scoring)
Direction: CV + Q&A (Q&A validates depth, influences scores)
What Happens with Verification Outcomes
| Q&A Result | Impact |
|---|---|
| ✅ Deep knowledge shown | Increases skill score |
| ❌ Weak understanding revealed | Lowers skill assessment |
| ⚠️ CV shows experience, Q&A weak | Active penalty — inconsistency flagged |
| 💡 Current knowledge demonstrated | Can validate dated CV experience |
Example: CV lists "React, Vue" but Q&A shows deep React expertise but only basic Vue knowledge → React score boosted, Vue score lowered
Key: Q&A provides current knowledge evidence and affects final scoring. Used as "supporting evidence" for overall fit.
🔍 Comprehensive: Multi-Aspect Validation
Direction: CV + Q&A (assesses skills, approach, communication, red flags)
What Happens with Verification Outcomes
| Q&A Aspect | Impact |
|---|---|
| Skill Depth | Validates beyond CV bullet points |
| Problem-Solving | Assesses approach and methodology |
| Communication | Evaluates clarity and thought process |
| Red Flags | Detects inconsistencies or concerning patterns |
Example: CV claims "led microservices migration" — Q&A reveals detailed technical approach, clear communication, and specific challenges overcome → High confidence score across multiple dimensions
Key: Q&A is a "Key Influencer" (35% weight). Actively pulls scores up or down based on multi-aspect validation.
🔬 Extended: Mandatory with Multipliers
Direction: CV ↔ Q&A (equal footing, bidirectional)
Q&A Validation Multipliers
| Validation Level | Multiplier | Meaning |
|---|---|---|
| Strong | 1.0× | Full credit — Q&A fully confirms CV |
| Adequate | 0.9× | Slight reduction — minor gaps |
| Weak | 0.7× | Significant penalty — Q&A undermines CV |
| Contradiction | 0.4× | Major penalty — direct conflict |
Example: CV claims "expert in AWS, GCP, Azure" — Q&A shows deep AWS knowledge but admits GCP/Azure only theoretical → AWS gets 1.0x, GCP/Azure get 0.7x multiplier
Hidden Strength Scenario: CV is vague but Q&A is strong → Partial bonus + interview flag to verify
Overstatement Scenario: CV strong but Q&A weak → 0.4x or 0.7x multiplier + Red Flag
Key: Mandatory structured qa_analysis_report produced. Q&A is "equal footing" with CV (40% weight).
🚀 Advanced: Primary Validator for Currency
Direction: Q&A → CV (Q&A validates recency, current knowledge is primary)
Q&A as Currency Validator
| Scenario | Q&A Impact |
|---|---|
| Dated CV + Modern Q&A | Q&A "saves" candidate — confirms currency |
| Strong CV + Outdated Q&A | Q&A "flags" candidate — knowledge decay detected |
| Skills used 3-5 years ago | 0.8x recency multiplier unless Q&A confirms current use |
| Skills used 5+ years ago | 0.5x recency multiplier unless Q&A confirms active use |
Example: CV shows "Hadoop experience (2018-2020)" — Q&A demonstrates current Spark/Kubernetes usage with no recent Hadoop → Hadoop marked as outdated (0.5x), Q&A validates shift to modern stack
Currency Rescue: Last used Python in 2019 but Q&A shows active Python projects in 2025 → Recency penalty waived, Q&A confirms currency
Currency Flag: CV claims "current with cloud-native" but Q&A reveals knowledge of deprecated patterns → Red flag: skill decay detected
Key: Q&A is "Primary Validator" for currency (45%+ weight). Special attention to recency of knowledge. outdated_skills and recency_note added to output.
🚩 Red Flag Detection by Level
Red flags identify concerning patterns that may indicate risk, dishonesty, or poor fit. Detection capability increases significantly at higher levels.
| Red Flag Type | Basic | Moderate | Comprehensive | Extended | Advanced |
|---|---|---|---|---|---|
| CV-Q&A Inconsistencies (Overstatement) |
✅ Yes | ✅ Yes | ✅ Yes | ✅ Yes | ✅ Yes |
| Employment Gaps | ❌ | ❌ | ❌ | ✅ Yes | ✅ Enhanced |
| Job Hopping Pattern | ❌ | ❌ | ❌ | ✅ Yes | ✅ Enhanced |
| Skill Decay / Outdated Knowledge | ❌ | ❌ | ❌ | ⚠️ Basic | ✅ Detailed |
| Certification Expiration | ❌ | ❌ | ❌ | ⚠️ Basic | ✅ Detailed |
| Career Trajectory Concerns | ❌ | ❌ | ❌ | ✅ Yes | ✅ With Momentum |
📋 Basic • Moderate • Comprehensive
Only detects CV-Q&A inconsistencies (overstatements). If CV says "expert" but Q&A reveals limited knowledge, this is flagged as a red flag indicating dishonesty or self-assessment issues.
🔬 Extended
Adds pattern-based red flags: employment gaps, job hopping, stagnant career. Also detects basic skill decay through CV timeline analysis. Includes structured red_flags array in output.
🚀 Advanced
All Extended flags PLUS enhanced recency analysis: explicit outdated_skills list, recency_note on certifications, and Q&A-validated currency checks. Detects when candidate's claimed current skills don't match their demonstrated knowledge.
📝 Example Red Flag Output (Extended+):
"red_flags": [ "CV-Q&A inconsistency: Claims 'expert in Vue.js' but Q&A states 'never used Vue professionally'", "Employment gap: 18-month unexplained gap between 2019-2020", "Job hopping: 4 positions in 3 years (2017-2020) — pattern of short tenure", "Outdated skill: Hadoop last used 2020, technology declining; no recent evidence" ]
Summary: Q&A Weight Progression
Basic
~10%
Verify only
Moderate
~20%
Depth check
Comprehensive
~35%
Multi-aspect
Extended
~40%
Multipliers
Advanced
~45%+
Currency validator
💡 Recommendation by Role Type
Entry-level, high volume: Use Basic
Mid-level, standard hiring: Use Moderate (default)
Senior IC, team leads: Use Comprehensive
Directors, VPs, specialized experts: Use Extended
C-suite, cutting-edge tech roles: Use Advanced
⚠️ Important Notes
- All levels use the same skill logic -
required_countinterpretation is consistent. - Higher levels don't change pass/fail criteria - they provide more depth and context.
- Q&A importance increases by level - **Basic: ~10% weight → Advanced: ~45% weight.**
- All levels can use both CV and Q&A - but they are weighted differently.
- Choose your level based on the consequence of a bad hire - higher stakes = higher level.
Cloud vs. Local LLM API Performance
When integrating large language models (LLMs) into applications, performance and scalability can vary significantly depending on whether the API is cloud-based or local:
- Cloud LLM APIs are rate limited and typically have higher latency due to network transmission times and shared resource constraints.
INFO:openai._base_client:Retrying request to /chat/completions in 0.383811 seconds
INFO:httpx:HTTP Request: POST https://.....azure.com/openai/deployments/gpt-5/chat/completions?api-version=2024-04-01-preview "HTTP/1.1 200 OK" - Local LLM APIs such as Ollama generally provide faster response times and are not rate limited, since requests stay on-device and depend solely on local compute capacity.
- Ollama offers strong single-request performance but can encounter scalability limitations when handling multiple concurrent workloads.
CV Analysis Dashboard
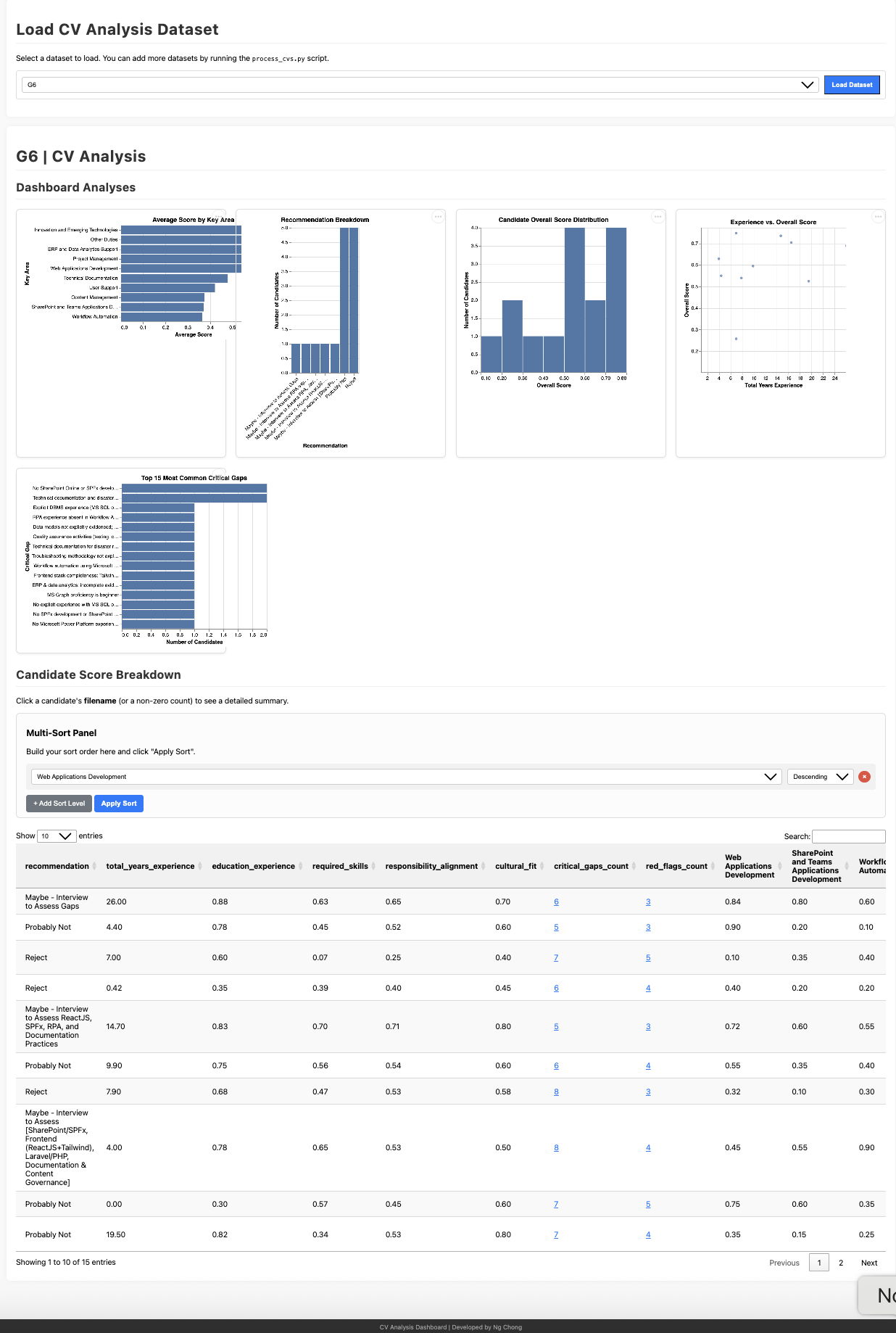
Key Use Case: Sort by Component Score, Not Just Overall
The dashboard allows you to sort candidates by scores in specific evaluation areas—Skills, Responsibility Alignment, Education & Experience, or Cultural Fit—rather than relying solely on the overall score.
This flexibility lets you prioritize what matters most for your specific hiring context:
- Technical-heavy role? Sort by Required Skills score to find the strongest technical candidates first
- Leadership position? Sort by Responsibility Alignment to prioritize candidates with proven scope and scale
- Junior role with growth potential? Sort by Cultural Fit and Education & Experience to find the best learners
- Specialized expertise needed? Sort by the specific component that matches your critical requirement
Example: For a research position requiring specific publications, you might sort by Responsibility Alignment to see who best matches the core research duties, even if their overall score is lower due to gaps in other areas.
Important Considerations: AI Limitations
While this tool significantly accelerates the initial review process by following your instructions, it is a tool designed to assist, not replace, human judgment and expertise.
📌 Research Context
This project describes an experimental, research-oriented exploration of AI-assisted screening. It is not a production HR system, nor does it represent United Nations University (UNU) hiring policy or procedures. The tool is designed for research and educational purposes to explore how AI might assist with initial CV screening processes.
- AI models can sometimes make mistakes, misinterpret nuances in resumes, or fail to capture the full context of a candidate's experience.
- AI evaluations can potentially reflect unintended biases. Using multiple models (a core feature) can help mitigate this.
- The quality of the AI's output is directly dependent on the clarity of the job description and the evaluation prompt you provide.
Therefore, always critically review the AI-generated evaluations. Use them as a starting point, but conduct thorough interviews and reference checks before making final hiring decisions.