Large language models (LLMs) excel at handling text, but they can stumble when it comes to answering questions about numerical data in tables. To explore this limitation, I tested how advanced models handle two common scenarios:
- Multi-page tables in PDFs: a PDF with a single table spanning three pages (downloadable here: https://datatables.net/extensions/buttons/examples/html5/pdfImage.html). The table contained employee details like name, position, salary, etc.
- Multiple tables in PDFs: a PDF with three tables (downloadable here: https://sedl.org/afterschool/toolkits/science/pdf/ast_sci_data_tables_sample.pdf).
Scenario 1 – Multi-page Table in a PDF
The task was to find employees earning between $70,000 and $100,000 (name and salary). The results were mixed. File uploads were unavailable in the free versions of Perplexity and ChatGPT without signing in, and the free version of Gemini did not support file uploads at all. While using the upload feature of Copilot (copilot.microsoft.com), I encountered inconsistent responses due to the probabilistic nature of LLMs, ranging from errors in reading the PDF to an inability to provide an answer.
As shown in Figure 1, none of the tested models (Copilot (copilot.microsoft.com), Perplexity, ChatGPT, Claude) provided the correct answer when the data was received in an already extracted, structured format. Only Gemini (presented in Figure 2) accurately answered the query in this format. While using the extracted data, Claude 3.5 Sonnet failed. However, after uploading the PDF file, it parsed and analyzed the data correctly.
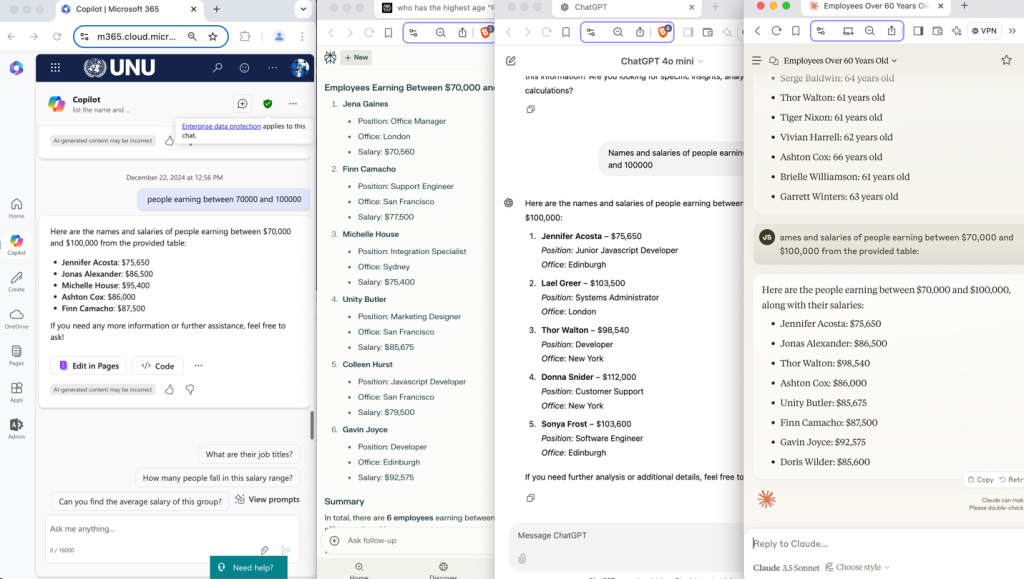
Figure 1 – Results from Copilot (copilot.microsoft.com), Perplexity (free plan), ChatGPT 4o mini (free plan), and Claude 3.5 Sonnet (free plan) (left to right).
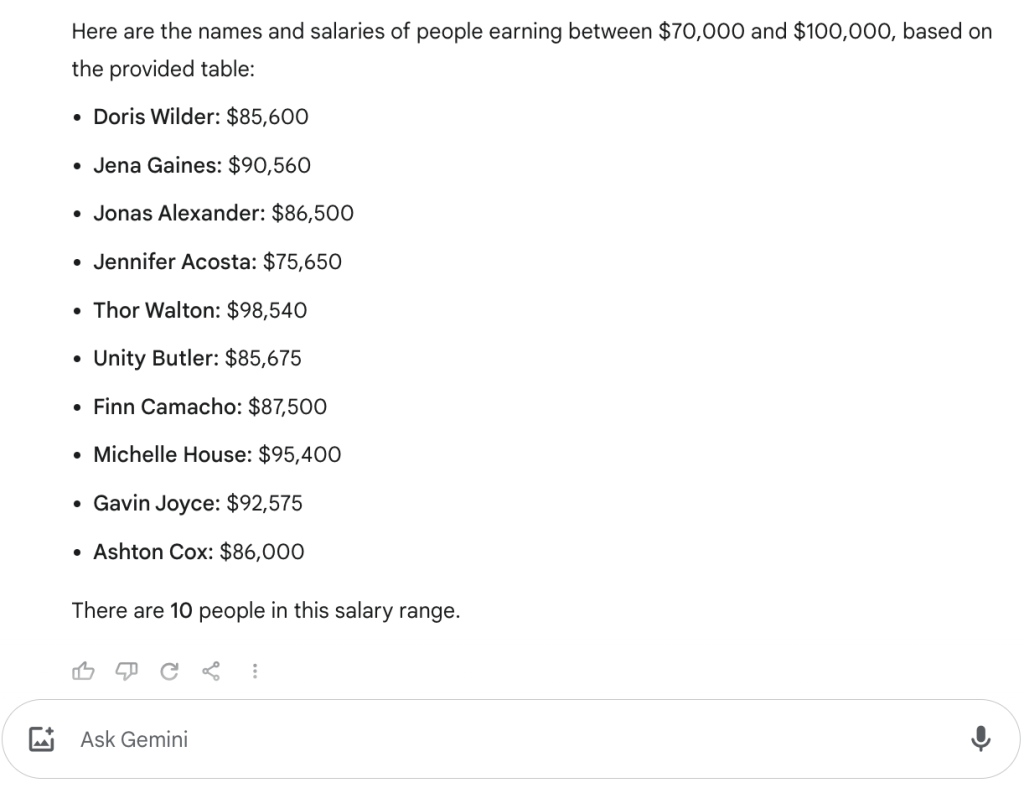
Figure 2 – Gemini correctly retrieved the requested information.
Scenario 2 – Multiple Tables in a PDF
The second scenario involved a PDF containing multiple datasets that could be potentially converted into tables. I focused on a table titled “Automobile Land Speed Records from 1963 to 1977,” containing details like speed, driver names, car names, etc.
The task was to identify all speed records between November 15th, 1964, and October 23rd, 1997. As illustrated in Figure 3, Copilot (copilot.microsoft.com) provided an incorrect answer, listing only 4 records. While these matched the criteria, Copilot missed retrieving all relevant entries. The complete and accurate results are shown in Figure 4. This negative result was consistent across all the platforms, including Gemini.
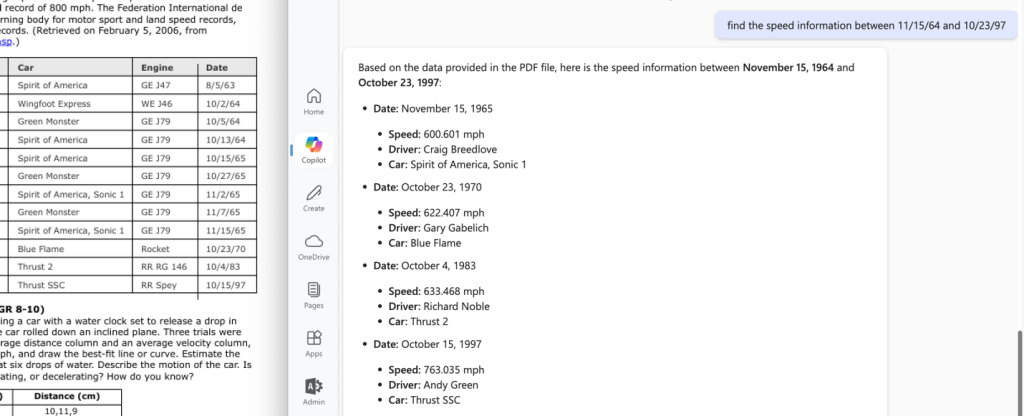
Figure 3 – Copilot (copilot.microsoft.com) couldn’t retrieve all speed records within the specified date range.

Figure 4 – My Python code (more details below) successfully identified all the matching records.
Extracting data from PDFs, especially tables, can be a real headache for even the smartest AI models like Copilot. Why? Let’s dive in:
Decoding PDFs – AI Challenges
1. PDFs are a Messy Format:
- Tables are Tricky: Imagine a perfectly organized spreadsheet – PDFs rarely live up to that ideal. You’ll find multi-level headers, cells merged across columns, and even footnotes tucked away, making it hard for AI to understand the structure.
- Inconsistent Styles: Fonts, sizes, and spacing can vary wildly, confusing the AI and hindering accurate data extraction.
- Multi-Page Tables: The AI must determine where one page ends and the next begins, which can be tricky.
- Images and Scans: Many PDFs contain images or scans of tables. This requires OCR (Optical Character Recognition) to convert images to text, and OCR isn’t always perfect, especially with low-quality images.
- Data Noise: Background colors, lines, and other visual elements can interfere with the AI’s ability to “see” the actual data.
2. AI’s Language-Centric Strengths:
- Born from Text: AI models like LLMs are masters of language. They thrive on text, learning patterns and relationships within words. But numbers are a different story.
- Numbers as Words: The AI might see numbers as just another word in a sentence, missing their true meaning as quantities or values. This limits its ability to perform calculations or comparisons.
3. AI Capabilities and Limitations:
- Pattern Recognition vs. Understanding: While AI systems excel at recognizing patterns, they may struggle with understanding the semantic meaning behind table structures and their contents. This can lead to errors when dealing with unusual or complex table formats.
- Numerical Processing: Modern AI models can handle both text and numbers effectively, but they may face challenges when required to perform complex calculations or comparisons across large datasets extracted from PDFs.
- Error Recovery: Unlike humans, AI systems may have difficulty detecting and recovering from extraction errors, especially when encountering unexpected formatting or content variations.
4. The Challenge of Context:
- Understanding Table Relationships: AI needs to grasp the intricate relationships between rows, columns, and headers within a table. This can be quite complex.
- Missing the Bigger Picture: Tables often rely on implicit information and real-world knowledge. For instance, a table might list ‘Sales’ without specifying the currency—something humans can easily infer, but AI may require explicit instructions for. Similarly, date information might be provided without a clear date format.
Processing Tabular Data from PDFs with LLMs
Direct extraction of tabular data from PDF documents proved unreliable, so I converted the PDF pages into images and leveraged the OCR capabilities of LLMs, specifically Gemini-2.0-Flash-Exp, to extract tables from these images and convert them into structured data. My experience demonstrated that LLMs are becoming increasingly effective at OCR tasks, making this image-based extraction method particularly promising.
Recognizing and Merging Multi-Page Tables
Helper functions were introduced to recognize and merge tables spanning multiple pages. This approach ensures data continuity, accurately reconstructs tables, and enables reliable data extraction and analysis.
On-the-Fly Code Generation for Data Queries
LLMs’ on-the-fly code generation capabilities were used to answer data queries, including generating plots and graphs. This feature enables dynamic interaction with the extracted data, providing visual representations that enhance understanding and support better decision-making
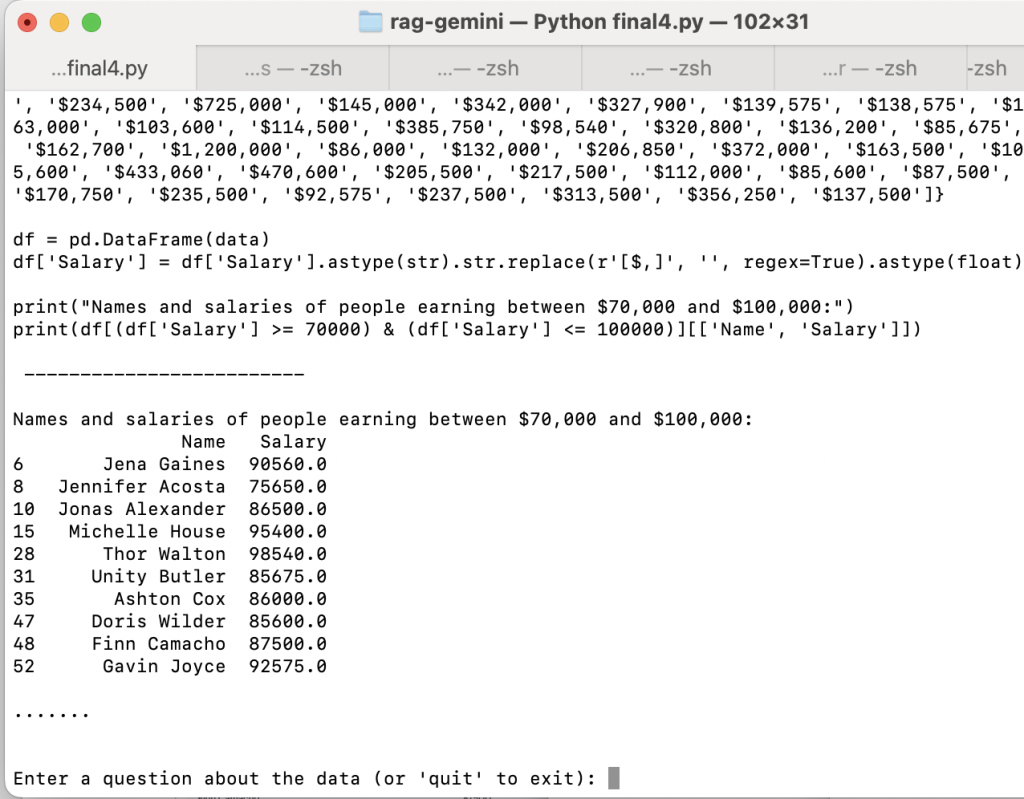
Figure 5 – My code first consolidated the rows from the multi-page table in scenario 1 into a single table before responding to queries.
Figure 6 – Output of my Python code showing the distribution of age by position.
I recognize that there are libraries designed for parsing PDF documents and processing tabular data with LLMs. However, it remains unclear how well these tools perform, especially in scenarios like Scenario 1 (with multi-page tables) and Scenario 2 (where understanding in-context information, such as date formats, is crucial). My goal was to gain insights into the specific challenges of processing tables from PDFs, particularly in these contexts.
PDF data extraction often requires a blend of AI capabilities, careful preprocessing, and, in some cases, human verification for critical applications. While modern AI models excel at pattern recognition, the challenge goes beyond simple PDF parsing. Today’s AI models are brilliant at recognizing patterns, but the task demands more than just parsing PDFs. It involves building intelligent systems via API-based interaction with AI models that can generate and execute code to manipulate the extracted data, perform validation checks, and enable interactive analysis.
Platforms like Copilot and Perplexity, which offer direct engagement, are making strides in handling structured data. However, they still face hurdles with complex table structures, contextual interpretation, and generating dependable code for data manipulation.