Deep Research tools are transforming the way we gather and analyze information by automating complex research processes. These tools analyze vast amounts of data, synthesize information, and produce detailed outputs—including summaries, citations, and source links—in a fraction of the time it would take a human researcher. At the core of this innovation are two key concepts: chain-of-thought (CoT) reasoning and test-time compute (TTC).
CoT reasoning enables AI systems to perform multi-step, human-like analyses during inference, breaking down complex queries into logical steps. Meanwhile, TTC refers to the computational resources allocated during inference, allowing models to “think longer” and produce more accurate, thoughtful responses to intricate questions. Together, these concepts empower Deep Research tools to deliver high-quality, context-aware insights.
Key Features of Deep Research Tools
Modern Deep Research tools come equipped with a range of advanced capabilities, including:
- Rapid task completion, accomplishing in minutes what might take humans hours.
- Autonomous web browsing and data collection from diverse online sources.
- Analysis of multiple data formats, such as text, images, and PDFs.
- Synthesis of information using sophisticated reasoning algorithms.
- Generation of structured reports complete with citations and source links.
The Rise of Deep Research Platforms
The Deep Research landscape has seen significant advancements with the launch of several high-profile tools:
- Gemini introduced Advanced Deep Research on December 11, 2024.
- OpenAI followed suit with its Deep Research offering on February 2, 2025.
- Perplexity.AI joined the fray on February 14, 2025, offering both free and paid tiers, with the latter priced at $20 per month.
- Grok 3, released on February 17, 2025, is available exclusively to X’s Premium+ subscribers at $50 per month. Grok 3 has introduced two distinct reasoning modes: “Think” and “Big Brain.” The “Think” mode processes queries step-by-step, making it ideal for tasks requiring structured logic. In contrast, the “Big Brain” mode leverages additional computational resources to tackle more complex problems, enhancing its problem-solving capabilities.
While Gemini, OpenAI, and Grok restrict their tools to paid users, Perplexity.AI stands out by offering a free tier, allowing signed-in users to perform up to three Deep Research queries daily. This approach not only enhances accessibility but also fosters community engagement and feedback.
Challenges and Considerations for Accessibility
Despite their transformative potential, Deep Research tools face significant accessibility challenges. Restricting these tools behind paywalls can:
- Limit valuable user feedback loops, slowing down model improvements
- Reduce word-of-mouth growth and user adoption
- Hinder opportunities for user education and professional development, as training resources concentrate on widely available platforms
- Slow the development of best practices and reduce chances of users discovering new or unexpected use cases, as fewer users share knowledge, and companies hesitate to integrate AI without free testing
- Give more accessible competitors a strategic advantage.
Perplexity.AI’s free tier represents a step toward addressing these challenges, promoting broader access while encouraging community involvement.
Limitations of Perplexity’s Deep Research
While Perplexity’s Deep Research tool offers advanced functionalities, it is not without limitations. These issues became apparent during my evaluation of the tool to generate a comprehensive report comparing Grok 3 with advanced reasoning models from OpenAI, Google, and DeepSeek. The assessment also sought to understand how Grok 3 selects and verifies sources to ensure accuracy, relevance, and authority.
Initial Test: Scholarly and Research Papers
In the first test, the search was restricted to scholarly and research papers. Despite scanning 120 academic websites, only eight sources were cited in the report. Most links were unrelated to the main topic, and none of the cited sources were relevant. For example, the report included a citation about a “Music Center in Banda Aceh” (https://www.semanticscholar.org/paper/Music-Center-In-Banda-Aceh%2C-Theme-%3A-Expressionist-Haji-Aini/8ae0932b6feada51b7c87aa1a93de4d6e8ea68c2), which had no connection to the research topic. Moreover, it is a paywalled resource, raising questions about how it could analyze it.
This outcome may stem from the limited coverage of Grok 3 in academic publications, given its proprietary nature. However, this also highlights a broader issue: AI models often deliver responses that are confidently written but factually inaccurate, underscoring the critical need for independent fact-checking. To build trust and reliability, these models must learn to recognize their limitations and respond with ‘I don’t know’ when appropriate, rather than generating speculative or incorrect information. This transparency would not only improve user confidence but also encourage a more responsible and ethical use of AI in research and decision-making.
Second Test: Web, Academic, and Social Sources
In the second test, the same prompt was submitted, allowing the use of web, academic, and social sources.
The tool reviewed 130 sources but cited only four Reddit links in the report. To verify the sources behind an informative table in the report below, I followed up to confirm the origin of ‘user reports[1-3]’.

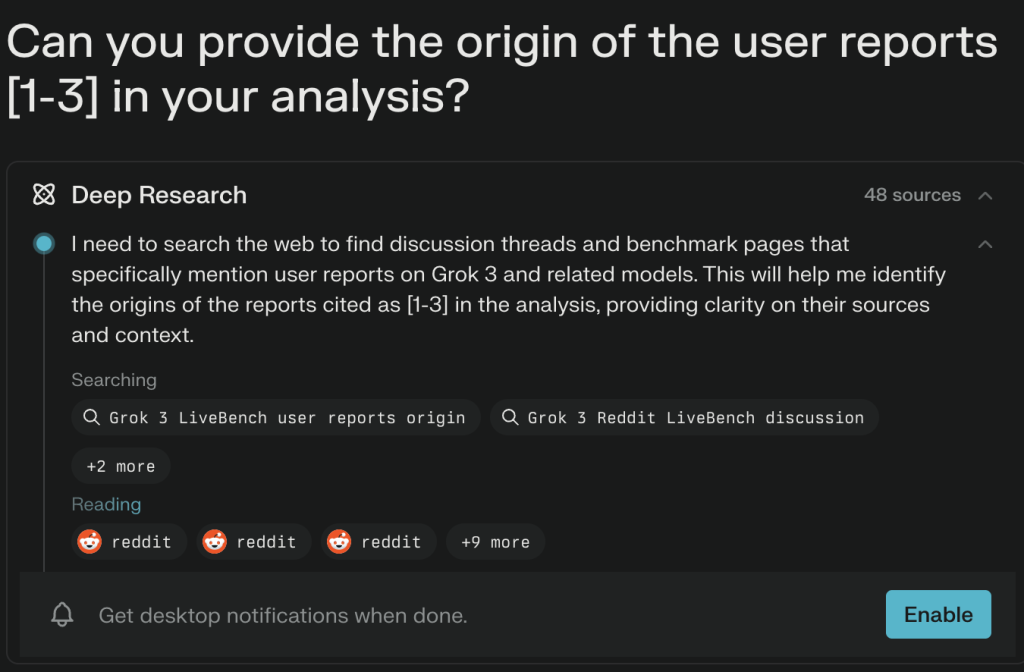
The tool provided the following references, which did not offer additional insights into the methodology used to generate the table:
https://www.reddit.com/r/Bard/comments/1is88d5/grok_3_is_what_gemini_20_pro_should_have_been/ [This is a new link]
https://www.reddit.com/r/ClaudeAI/comments/1hhe7hb/claude_seems_less_helpful_last_23_days/ [This is a new link]
https://www.reddit.com/r/ClaudeAI/comments/1is6ncb/grok_3_released_1_across_all_categories_equal_to/ [This is a new link]
https://www.reddit.com/r/singularity/comments/1isishj/grok_3_not_performing_well_in_real_world/ [This link appears in the report where the metrics were identified]
If the new links supported the metrics, their exclusion from the first report was surprising. Moreover, the initial AI-generated report included a section on source verification, while the second one did not. This suggests high variability in output, particularly regarding alignment with the research points, despite using the same prompt.
The limitations observed can be grouped into three main areas:
- Accuracy and Reliability Issues: The tool may generate plausible but inaccurate information and treat unreliable sources as equivalent to verified ones, emphasizing the need for independent verification.
- Communication of Uncertainty: The tool often fails to convey uncertainty, potentially misleading users into over-trusting its outputs without sufficient skepticism.
- Formatting Inconsistencies: The report’s Markdown formatting replaced references that did not match those provided in the web version, creating discrepancies.


Reference 2, listed as 7 in the web version, is available at [https://arxiv.org/abs/2310.13061 – ‘To grok or not to grok …’]. The web version also includes references 2 and 7, with 2 missing in the markdown: [https://www.semanticscholar.org/paper/Resistance-ratio-read-(R-sup-3-)-architecture-for-a-Inaba-Tsuchida/ – Resistance ratio read (R/sup 3/) architecture …].
Conclusion
Deep Research tools represent a significant leap forward in automating complex research tasks, offering unprecedented efficiency. However, challenges related to accessibility, accuracy, and reliability must be addressed to fully realize their potential. The study also suggests Perplexity’s Deep Research faces challenges with the latest developments and likely performs better when analyzing established topics.
Offering free tiers can substantially influence accessibility and user adoption. Free tiers provide a cost-effective means for users to explore the tool’s features without financial commitment, thereby reducing the entry barrier and fostering experimentation and feedback. This strategy can result in a broader user base and yield valuable insights for continuous improvement.
As these tools continue to evolve, it will be essential to foster transparency, particularly regarding the criteria used to differentiate between authoritative and less credible sources. Improving source verification and enhancing user education will also be critical to their success. In the meantime, users should approach AI-generated insights with a healthy dose of skepticism and always verify critical information independently.